Compiler Design Laboratory
1. Automatic generation of MiniJava lexical and syntactical analyzer
1.1 Introduction
JavaCC (Java Compiler Compiler) is a syntactic and lexical analyzer generator. JavaCC entry will receive a description language as a grammar and will generate Java code that will read and analyze that language. JavaCC can be downloaded for free at https://javacc.github.io/javacc/ web site. This parser generator has a rich thesaurus of grammars of known languages like: C, C++, Java, HTML, PHP, SQL, Python, etc.
1.2 The JavaCC grammar format
In order to generate a lexical analyzer and a syntactical analyzer the grammar needs to follow a standard format. Grammars begins with a section for declaring options followed by a block in a "PARSER_BEGIN(name)" and "PARSER_END(name)". If the name has the value of "MyParser" then the generated files will be:
- MyParser.java - contains the syntactical analyzer
- MyParserTokenManager.java - contains the lexical analyzer
- MyParserConstants.java - contains different constants for the analysis process
Other files may also be generated.
The content of a Java compilation unit must be placed in the block enclosed by PARSER_BEGIN and PARSER_END. This compilation unit has the content of a regular Java file. Provided that such a grammar is correct and the parser name is the same in all three occurences, that part of the grammar looks as follows:
PARSER_BEGIN (MyParser)
...
class MyParser
{
...
}
PARSER_END (MyParser)
The generator does not check the syntactical errors in this section of the grammar and that they can be propagated in the generated analyzer, so code and errors may appear at compile time.
Using the package definition in the compilation unit all generated files will be placed in the very same package.
The analyzer file contains everything written in the compilation unit plus the generated parser located at the end of the file.
...
class MyParser...
{
...
// the generated parser is inserted here
}
...
The generated parser is a descendent recursive one and it contains an analysis method for each nonterminal of the grammar.
1.3 JavaCC generation options
The generator options can be declared either in the grammar or they can be called from the command line. Command line options have higher priority than those placed in the grammar.
javacc_options ::= [ "options" "{" ( option_binding )* "}" ]
The list of options begins with the "options" keyword followed by a list name = value statements grouped into a block marked by braces. Option names are not case sensitive.
option_binding::= "LOOKAHEAD" "=" java_integer_literal ";" | "CHOICE_AMBIGUITY_CHECK" "=" java_integer_literal ";" | "OTHER_AMBIGUITY_CHECK" "=" java_integer_literal ";" | "STATIC" "=" java_boolean_literal ";" | "SUPPORT_CLASS_VISIBILITY_PUBLIC" "=" java_boolean_literal ";" | "DEBUG_PARSER" "=" java_boolean_literal ";" | "DEBUG_LOOKAHEAD" "=" java_boolean_literal ";" | "DEBUG_TOKEN_MANAGER" "=" java_boolean_literal ";" | "ERROR_REPORTING" "=" java_boolean_literal ";" | "JAVA_UNICODE_ESCAPE" "=" java_boolean_literal ";" | "UNICODE_INPUT" "=" java_boolean_literal ";" | "IGNORE_CASE" "=" java_boolean_literal ";" | "USER_TOKEN_MANAGER" "=" java_boolean_literal ";" | "USER_CHAR_STREAM" "=" java_boolean_literal ";" | "BUILD_PARSER" "=" java_boolean_literal ";" | "BUILD_TOKEN_MANAGER" "=" java_boolean_literal ";" | "TOKEN_EXTENDS" "=" java_string_literal ";" | "TOKEN_FACTORY" "=" java_string_literal ";" | "TOKEN_MANAGER_USES_PARSER" "=" java_boolean_literal ";" | "SANITY_CHECK" "=" java_boolean_literal ";" | "FORCE_LA_CHECK" "=" java_boolean_literal ";" | "COMMON_TOKEN_ACTION" "=" java_boolean_literal ";" | "CACHE_TOKENS" "=" java_boolean_literal ";" | "OUTPUT_DIRECTORY" "=" java_string_literal ";"
The most important options are explained below:
LOOKAHEAD: This option is set to default value 1. It specifies the number of atoms that are read in advance in order to make decisions during the analysis. As this option value is smaller the parser has greater speed. This option can also be changed locally for some grammar rules.
CHOICE_AMBIGUITY_CHECK: This option is set to default value 2. It is anticipated the number of atoms to check when the rules that have ramifications ambiguity like "A | B |...". For example if A and B have common prefixes of two atoms, but not of three atoms and assuming the constant value is set to 3, the generator will recommend a value of 3 for the lookahead option in order to eliminate the ambiguities. If A and B have a common prefix of three atoms JavaCC will recommend a value of 3 or more for the lookahead option. Increasing this value can significantly slow the parsing process.
OTHER_AMBIGUITY_CHECK: This option is set by default to value 1. It is used to count the number of atoms analyzed in advance to remove ambiguity in the context of choices like "(A)*", "(A)+", "(A)?". This value is recommended to be set to 1 and not to 2 because it takes more time to do the checking than in the case of choice checking.
STATIC: This is option is set by default to true. In this case all members and methods in the generated parser class are declared as static. This decision allows the existence of a single instance of the parser to be present in an application, but with increased performance. In order to run multiple tests during a session running the analyzer we have to call the ReInit() method to reinitialize the parser. If the parser is non-static new parser instances can be created using the new operator. The parser instances can be used in different threads.
DEBUG_PARSER: This is option is set by default to false. When it is set to true the parser will generate a trace of all its actions. Using calls like disable_tracing() and enable_tracing() in the grammar code, we can activate tracing only in the grammar parts where needed.
DEBUG_LOOKAHEAD: This option is set by default to false. When it is set to true and in combination with the DEBUG_PARSER option it will provide you a trace of actions executed during a lookahead operation.
DEBUG_TOKEN_MANAGER: This option is set by default to false. When it is set to true the generated token manager will produce a trace of its actions.
ERROR_REPORTING: This option is set by default to true. Setting this option to false will display a less detailed error analysis, in order to increase performance.
IGNORE_CASE: This option is set by default to false. Setting it to true will cause the lexical analyzer to take into account the difference between uppercase or lowercase characters.
OUTPUT_DIRECTORY: This option is a string whose default value is the current directory. This controls the directory where the output parser files are generated.
For more options you should check the official documentation at https://javacc.java.net/doc/javaccgrm.html.
1.4 JavaCC Grammar Productions
JavaCC grammar has four kinds of productions.
production ::=
javacode_production
| regular_expr_production
| Bnf_production
| token_manager_decls
The "javacode_production" and "bnf_production" are used to define the grammar that generates the analyzer. The "regular_expr_production production" is used to define tokens. The lexical analyzer is generated automatically from these rules. The "token_manager_decls" production is used to introduce declarations in the generated lexical analyzer.
1.4.1 Java Code Productions
javacode_production ::= "JAVACODE"
java_access_modifier java_return_type java_identifier "(" java_parameter_list ")"
java_block
The "javacode_production" is a way to write Java code for some productions instead of using EBNF rules. This is useful when it is necessary to recognize context dependent lists of tokens or complex analysis. An example is given in the code below:
JAVACODE
void skip_to_matching_brace()
{
Token tok;
int nesting = 1;
while (true)
{
tok = getToken(1);
if (tok.kind == LBRACE) nesting++;
if (tok.kind == RBRACE)
{
nesting--;
if (nesting == 0) break;
}
tok = getNextToken();
}
}
In this example the rule "skip_to_mathing_brace" will consume all the atoms from the stream until it findes a matching closed brace. The open bracket is considered that it has just been analyzed:
JAVACODE blocks are considerred by the parser generator as black boxes an they cannot reason especially when they apear at choicepoints like in the next example.
void NT() :
{}
{
skip_to_matching_brace()
|
some_other_production()
}
JavaCC generator will not know how to choose between the two versions. If JAVACODE blocks are used in places where no branch decisions are taken then there are no problems:
void NT() :
{}
{
"{" skip_to_matching_brace()
|
"(" parameter_list() ")"
}
In decision points JAVACODE productions may be preceded by lookahead mechanism having syntactical or semantical nature, like the following:
void NT() :
{}
{
LOOKAHEAD( {errorOccurred} ) skip_to_matching_brace()
|
"(" parameter_list() ")"
}
The default modifier for JAVACODE productions is package private.
1.4.2 BNF Productions
bnf_production:: =
java_access_modifier java_return_type
java_identifier "(" java_parameter_list ")" ":"
java_block
"{" expansion_choices "}"
BNF productions are the standard productions used by JavaCC grammars. Each production has a left hand side non-terminal specification. The right hand side of the BNF production defines the BNF non-terminal expansion. The non-terminal is described exactly like a Java method and it will be translated into a Java method in the generated parser. The non-terminal and the associated method will have the same name. The parameters and the return value can be used to transmit information upward andn downward in the analysis tree. The non-terminals appearing on the right side of a production are implemented as method calls. The propagation and recovery of values are implemented by the method call paradigm using input parameters and returned output values. The BNF productions access modifier is public.
The right side of a BNF production has two parts. The first one is a block of declarations and Java code. This code will be generated at appropriate non-terminal method. Every use of the rule implies the code to be executed. Statements from this part are visible in all the Java code of any semantic actions that are inserted into the right side of that rule. The generator makes no checking to the inserted code, it just reads through your code until the last close bracket. Thus, eventual errors can be propagated in the code of the generated analyzer.
The right side of the rule has a second component that represents an expansion of the BNF, which will be described later.
1.4.3 Regular Expression Productions
regular_expr_production ::=
[ lexical_state_list ]
regexpr_kind [ "[" "IGNORE_CASE" "]" ] ":"
"{" regexpr_spec ( "|" regexpr_spec )* "}"
Productions based on regular expressions are used to define lexical entities that are to be processed by the lexical analyzer.
A production based on regular expressions begins with specification of the lexical states of the rule where it applies. There is an implicit lexical state called DEFAULT. If the state list is omitted then the lexical rules production is applied to the DEFAULT state.
Next, follows a description of the type of regular expression that will be used. The types of regular expressions are defined below.
After this option may appear the IGNORE_CASE keyword. If present the productions based on regular expressions will be insensitive to differences in uppercase and lowercase. The efect is the same as with IGNOR_CASE, but in this case it applies only to local production based on global regular expression and not the entire grammar.
The construction is then followed by a list of specifications of regular expressions that are describe in more detail production lexical entities based on regular expressions.
token_manager_decls ::= "TOKEN_MGR_DECLS" ":" java_block
Statements for the lexical analyzer begin with the keyword TOKEN_MGR_DECLS followed by ":" and a set of Java statements and instructions. These statements and instructions are written in the lexical analyzer generated lexical and are accessible to semantic actions.
There may be a single statement for the lexical analyzer in a JavaCC grammar file.
lexical_state_list ::= "<" "*" ">" | "<" java_identifier ( "," java_identifier )* ">"
The list of lexical states describes a set of states where productions based on regular expressions are applied. If the list of states is marked by "<*>" then the production based on regular expressions apply to all lexical states. Otherwise it aplies only to lexical states declared in the identifiers list between "<" and ">".
regexpr_kind ::= "TOKEN" | "SPECIAL_TOKEN" | "SKIP" | "MORE"
This rule specifies the four types of productions based on regular expressions:
- TOKEN: regular expressions in this production based on regular expressions describes the atoms in the grammar.
The lexical analyzer creates a Token object for each match of the regular expression and returns it to the analyzer.
- SPECIAL_TOKEN: regular expressions in this production are based on regular expressions describing the special atoms.
Special atoms are like ordinary atoms, but they are not important during the analysis, being
ignored by BNF productions.
Special atoms are still analysed by the parser to perform various actions.
They are analyzed by the parser and they are attached to atoms that matter in their neighbourhood.
For these atoms there can be used the specialToken field from the Token class.
Special atoms are useful in lexical entities analysis such as comments, which do not have
significance in terms of analysis, but nevertheless represents an important part of the input file.
- SKIP: The regular expression matched in this production based on regular expressions is ignored by the lexical analyzer.
- MORE: Sometimes it is useful to build gradually an atom to be deliverred to the syntactical analyzer.
The match of such a regular expression is stored in a buffer until the next match of a TOKEN or SPECIAL_TOKEN.
All the matches in the buffer and last match of a TOKEN or SPECIAL_TOKEN will be concatenated to form a new token or SPECIAL_TOKEN.
If there is a regular expression matching SKIP in the context of MORE match sequence then the buffer content is emptied.
regexpr_spec ::= regular_expression [ java_block ] [ ":" java_identifier ]
The regular expression specification represents actually the description of lexical entities that are part of the production based on regular expressions. Each production that based on regular expressions can contain any number of regular expressions specifications.
Each regular expression specification contains a regular expression followed by an optional Java code block in which we write the lexical semantical actions. Next, an identifier of a lexical state follows, which is also optional. For every regular expression matching, existing semantic actions are executed followed by joint actions of all atoms. Then type specific action is performed based on the regular expression production. If a lexical state is specified then lexical analyzer jumps to that state for further analysis. Initially, the lexical analyzer jumps to "DEFAULT" state.
expansion_choices ::= expansion ( "|" expansion )*
Expansion choices are written as a list of one or more expansion separated by "|". The legal sets of analyses allowed by the expanded version permits a legitimate analysis of each from the list of expansion choices.
expansion ::= ( expansion_unit )*
An expansion is described as a sequence of expansion units. The analysis effect consists in linking the effects made by expansion unit analyses.
For example, expansion of the rule "{" decls() "}" consists of three units component expansion "{", decls() and "}". A match of the expansion results from linking expanded matches individual units, in this case is any string that begins with "{" ends with "}" and it contains a match for decls() between the two braces.
expansion_unit ::=
local_lookahead
| java_block
| "(" expansion_choices ")" [ "+" | "*" | "?" ]
| "[" expansion_choices "]"
| [ java_assignment_lhs "=" ] regular_expression
| [ java_assignment_lhs "=" ] java_identifier "(" java_expression_list ")"
A unit can be expanded and local lookahead specification. This statement generated analyzer helps to choose alternatives in branch points of the rules.
An expanded unit consists of a set of Java and Java code statements marked by braces. They are also called stock analysis. This code is generated in the corresponding analysis method neterminalului appropriate position. This block will be executed each time the analysis goes through that point successfully. When the generator processes Java code block, he will not perform any semantic or syntactic verification. Exte possible that this block of code errors to be propagated to the Java compiler. Shares of analysis is not performed during analysis of the mechanism of lookahead.
A unit can be expanded a set of one or more expansion options grouped between parentheses.
A correct analysis of an expanded unit is the correct analysis on any expanded versions.
Expanded set of brackets can be optionally followed by:
- "+" Means a correct match involves repetition of an expanded unit or units often expanded
matching parenthesis;
- "*" Means match correctly expanded unit involves the repetition of zero or more times to match
expanded units in parentheses;
- "?" A correct analysis of the expanded unit is either an empty sequence of atoms or units foamed
incuibate correct match. Alternative syntax for this construction is to guard blowing variants
between square brackets "[...]".
A unit can be a regular expression expanded. A correct analysis of the expanded unit is the regular expression matches any atom. When such a match regular expression then create an object of type Token. This object can be accessed by assigning it to a regular expression by prefixing the variable construction of "variable =". In general the right of an assignment may be another award. This award is not executed during the assessment mechanism of lookahead.
A unit can be expanded non-terminal branches in the last case of the above rule.
In this case it takes the form of a method call to a nonterminal name used as a method.
A valid analysis to determine the actual parameters of neterminalului call nonterminal to be used in calculations and if the return type is void then it will return a value.
The return value can be assigned a variable that prefixes optional regular expression with the construction of "variable =".
In general the left assignment operator can find any valid assignment.
This is not executed during the assessment mechanism of lookahead.
Nonterminals expansions can not be used to introduce the left recursion, generator JavaCC will verify this.
local_lookahead ::= "LookAhead" ("[ java_integer_literal ] [""]
[ expansion_choices ] [""] ["{" java_expression "}"] ")"
Local lookahead specification is used to influence how decisions in the generated parser branch points of the rules. A local specification of lookahead lookahead begins with the keyword followed by a set of constraints separated by parentheses. There are three types of constraints for the mechanism of lookahead:
- lookahead limit designated by the full constant;
- lookahead expansion options based on syntactic and semantic lookahead expressed by the words of braces.
A brief description of each type of constraint lookahead mechanism is given below:
Lookahead limit
The maximum number of atoms that are analyzed in advance to determine the
choice of a variant of the analysis of a branching point. This whole option overrides the value
set by the lookahead. This limit applies only branch points located in areas where lookahead is
written statement. If lookahead statement was not a branch point where lookahead limit is ignored.
Syntactic lookahead
This is given by an expansion (expansion or alternative) that are used to
determine whether the choice of a variant of this analysis is correct. If lookahead statement was
not a branch point where your syntactic lookahead is ignored.
Semantic lookahead
This is a Boolean expression that is evaluated whenever oride analyzer passes through that point in time analysis.
If the expression is evaluated as true then the analysis continues normally.
If the expression is evaluated as false and the declaration of a local lookahead is reamificatie a point where the current alternative is abandoned and it goes next.
If the expression is negative and is not placed in a branch point where analysis stops with the error message.
Unlike other types of constraint, it is always evaluated.
In fact, the semantic lookahead is evaluated even if met during syntactic lookahead evaluation of other statements.
Default values for lookahead constraints
If the local lookahead specification of a date, but not all constraints have been included when the lack of default values are assigned as follows:
- If not specified a limit of only one lookahead lookahead and syntactic type is present when the lookahead limit is set on the highest integer value (2147483647).
In essence so your infinite lookahead is implemented, that is analyzed in advance how so many atoms are needed to find a match for your syntactic lookahead time.
- If not specified no limit and no lookahead lookahead syntax and assuming that there is a semantic lookahead, lookahead limit is set by default to 0.
This means that the syntactic lookahead is not your run, just semantic.
- If your syntactic lookahead is not given then the default value of lookahead is the alternative site where lookahead is applied locally.
If the local lookahead specification is not a decision point when your syntactic lookahead is ignored, so its value is irrelevant.
- If your semantic lookahead is not given then it is the default Boolean value of true.
Regular_expression ::= java_string_literal | "<" [ [ "#" ] java_identifier ":" ] complex_regular_expression_choices ">" | "<" java_identifier ">" | "<" "EOF" ">"
There are two places where the grammar of regular expressions can be written:
- Inside a regular expression specifications (part of a production based on regular expressions)
- As an expansion to an expansion mode. When a regular expression is used in this way, it's like
the regular expression should be defined as the current location and then referenced on a label
in the expansion module:
TOKEN :
{
regular expression
}
Below we describe the syntactic constructions of regular expressions.
The first type is the constant regular expression string. Entry analyzed match the regular expression if the lexical analyzer is in the state for which the regular expression applies if the following set of characters is identical to the constant string.
A regular expression can also be a complex regular expression using regular expressions more complex than we can provide the strings. Such a regular expression is placed between parentheses "<...>", sharp and can be labeled with an optional identifier. This tag can be used to cover the expanded regular expression or other units of the regular expressions. If the label is preceded by the sign "#" then the regular expression can not be expanded but only referenced in the units of other regular expressions. When the sign "#" is present when the regular expression regular expression is called.
A regular expression may be a reference to another labeled in which case regular expression is written as a label in brackets sharp "<...>".
A regular expression may be a reference to a predefined regular expression that matches the end
Regular expressions are also seen by the atoms lexical analyzer. Their purpose is to facilitate the definition of one or more complex regular expressions.
Take the example of rules that define FOLLOWING floating-point constants in Java:
TOKEN :
{
< FLOATING_POINT_LITERAL:
(["0"-"9"])+ "." (["0"-"9"])* ()? (["f","F","d","D"])?
| "." (["0"-"9"])+ ()? (["f","F","d","D"])?
| (["0"-"9"])+ (["f","F","d","D"])?
| (["0"-"9"])+ ()? ["f","F","d","D"]
>
|
< #EXPONENT: ["e","E"] (["+","-"])? (["0"-"9"])+ >
}
In this example FLOATING_POINT_LITERAL atom is defined using the definition of another atom called Exponent. The symbol "#" in front of Exponent label indicates that it exists only to define constribui other atoms, in this case FLOATING_POINT_LITERAL. Defining FLOATING_POINT_LITERAL atom is not affected by the presence or absence of the symbol "#". Instead, behavior is affected by the lexical analyzer. If the symbol "#" is omitted when the lexical analyzer will erroneously recognize strings such as an atom Exponent E123 instead consider it as an atom identifier of the Java grammar.
complex_regular_expression_choices ::= complex_regular_expression ( "|" complex_regular_expression )*
Regular expressions are altrnative complex consisting of a list of one or more complex regular expressions separated by the symbol "|". A regular expression matching is given by the complex alternative regular expressions to match any complex constituent.
complex_regular_expression ::= ( complex_regular_expression_unit )*
A complex regular expression is a sequence of modules of complex regular expressions. A match consists of a complex regular expression matches the concatenation of modules containing complex regular expressions.
complex_regular_expression_unit ::= java_string_literal
| "<" java_identifier ">"
| character_list
| "(" complex_regular_expression_choices ")" [ "+" | "*" | "?" ]
A complex regular expression module can be any string constant, in which case there is only one matching string that is himself.
A module that contains a complex regular expression can be a reference in another regular expression. This should be labeled to be referenced. Matches the regular expression matches involving all manner of complex components. References in regular expressions can not introduce cycles in the dependency between atoms.
A module that contains a regular expression can be a list of characters. A list of characters is one way to define a set of characters. A match for this type of module that contains the regular expression is given by any carcter is present in the list of characters.
A module that contains a regular expression can be a set of regular expressions alterntive. In this case, a matching module's components on alternatives matches. The set of alternatives can be optionally followed by: - "+" Module A match involving one or more repetitions of the matches for the set of alternatives in brackets. - "*" Every module involves matching zero or more repetitions of the matches for the set of alternatives in brackets. - "?": Any module matching involves matching the empty string or a set of alternatives in brackets.
Unlike regular expression "[...]" BNF expansions is not the same as building [...] "(...)?", regular expression is used to describe lists of characters in regular expressions.
character_list ::= [ "~" ] "[" [ character_descriptor ( "," character_descriptor )* ] "]"
The lists describe the character sets of characters. A match for a character list is any character in this crowd. A list of characters is a list of descriptors of characters separated by commas and located between brackets. Each character descriptor describes a single character or a character field. If the character list is prefixed with the symbol "~" then is the character set is any Unicode character in the set is not specified.
character_descriptor ::= java_string_literal [ "-" java_string_literal ]
A descriptor of characters can be one constant character, in which case the lot is described as a single item or two characters separated by "-", in which case describes the set of all characters in the range including its ends.
1.4 Using JavaCC from Eclipse
JavaCC parser generator can be used inside the Eclipse environment (www.eclipse.org) using a JavaCC Eclipse plugin. The plugin can be downloaded at http://eclipse-javacc.sourceforge.net/.
In order to implement a project which uses JavaCC Eclipse proceed according to the following steps:
1. Create a new file of type JavaCC
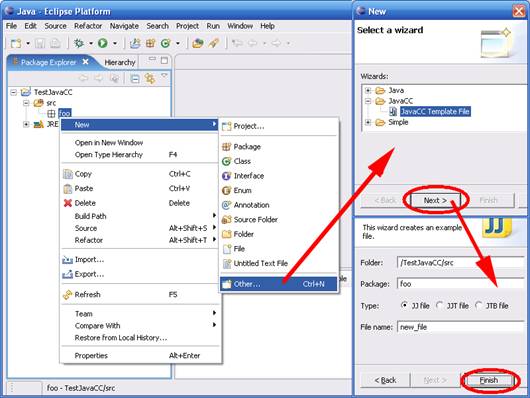
2. The parser generator will compile the the newly created JavaCC file generating the Java parser
files inside the current project.
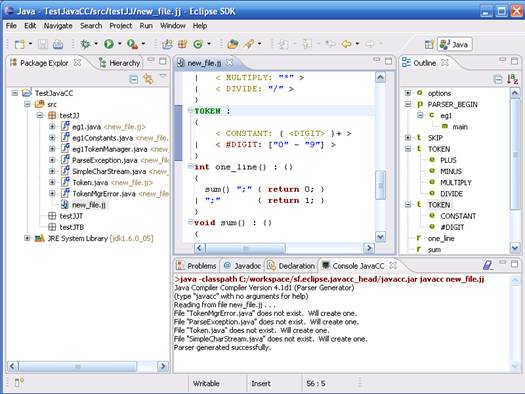
A detailed study of generator use can be made using the JavaCC documentation posted on page https://javacc.github.io/javacc/.
1.5 Assignments
1. Download the latest eclipse version from the Internet.
i) Unzip the instance on your hard drive.
ii) Download the JavaCC plugin using the Help menu, Software updates option, google for the
update link.
iii) Download JavaCC.zip standalone version of JavaCC from https://javacc.github.io/javacc/.
iv) Unzip and test the examples found there.
2. For the grammar given in file MiniJava.txt do the followings:
i) write the lexical analyzer rules;
ii) write the syntactical analyzer rules;
iii) eliminate grammar ambiguities by using the LOOKAHEAD, CHOICE_AMBIGUITY_CHECK,
OTHER_AMBIGUITY_CHECK options;
iv) generate the whole parser;
v) test the parser with hand made input MiniJava files;
vi) put the parser in debug mode to see how it works using the DEBUG_PARSER option.
Assignments time: weeks 1 and 2