Distributed Software Systems
This text is © by Dan Cosma
1. Definition
Referring to a larger context that includes both hardware and software, A.S. Tanenbaum defines a distributed system as ”a collection of independent computers that appears to its users as a single, coherent system”[TS01]. The various components of the system are dispersed at different geographical locations, and act together to fulfill the same goals. The inter-comunicating hardware nodes are connected to each other by a large variety of communication infrastructures, and many of the architectures implied are heterogenous in nature.
The continuous evolution of the society led to the current state of human activities, where organizations, companies or even communities depend on distributed infrastructures to communicate, collaborate and work. The wide variety of interdependencies between the components of our civilization, and their impact in creating and maintaining highly integrated networks of inter-related activities need to be supported by equally complex and developed technological solutions. Therefore, modern distributed systems could not serve their purpose without advanced and elaborate software applications to provide the diverse functionalities specific to each of the different types of problems addressed by the distributed contexts.
The distributed software systems are not simple conduits for the casual communication between parties, they must be designed to address the complex issues of intermediating and coordinating the distributed interaction.
A distributed software system can be defined and represented as a set of an arbitrary number of processing elements running at different locations, interconnected by a communication system [Wu99]. The processing elements are relatively independent software components that run on different hardware nodes and communicate to each other so that the design requirements are met. The communication is done via an infrastructure, implemented itself in software, that provides services for transporting data between the remote locations, coordinating asynchronous events, managing the concurrent interactions between the system components, and so on. The infrastructure can be represented by various layers of software, some being distributed systems themselves: services implemented in the operating systems, specialized middleware such as object request brokers [Sie96, RR02, Gra06], message-centered communication providers [MH00], application servers that provide distribution services ([MH99]), etc.
The different software nodes usually act as independent entities. That is, an important part of their activity is concerned with providing local features, such as interacting with the user or performing tasks that process local resources. The communication with the other components over the network is done only at the moments it is needed to maintain the overall system functionality, and many distributed components tend to minimize the communication as it usually implies significant costs.
Nevertheless, there are systems that consist of components that heavily communicate to each other during the entire running order of the application. They are either deployed on infrastructures able to provide high bandwidth and low latency for the data transfer, or the communication is done in short bursts that do not overload the network.
The aspects related to the communication and the system-wide inter-dependencies between the application entities are specific to its distributed architecture. The distributed architecture of the system is a view on a system’s structural characteristics that present the relations that are established over the communication infrastructure.
It specifies the communication channels, the roles of the components that communicate remotely, and it usually ignores the other architectural traits that were defined at the design time.
Consequently, extracting the distributed architecture of a system is not always the same as the general architecture recovery enterprises that treat the application without considering its distributed nature. Indeed, applying such a process to a distributed software system ends by providing architectural views on the system, by analyzing the various types of dependencies between the system entities. However, as the process did not analyze the nature of these dependencies in relation to the distribution-aware function of the application, it may miss the most significant trait of the application, the fact that it is distributed and the way the distribution impacts its design.
For example, if we were to analyze a simple chat system from a point of view that is not interested in its distributed aspect, the analysis will find that the application is one heavily concerned with providing a way for the user to enter text data via an interactive window, storing the text content when the user chooses to, checking the spelling of the phrases as they are typed, and managing the user/password information for authentication purposes. Dependencies on other instances of the chat component may be detected, however, they will not tell us anything about the fact that the communication is done remotely and the main concern of the application is the sending and receiving the messages, rather than storing them locally. In this respect, the application wouldn’t seem that different from a rather simple text editor.
2. Distributed Architectures
There are several types (patterns) of distributed architectures that are adopted by most applications that are made of components communicating over the network. A single application can be designed as following exactly one of these ‘classic’ architectures, or – most frequently – it employs a combination of the basic types, components having different architectural roles according to the purposes of the system.
2.1 Client-Server
The most common, widely-used distributed architecture is the client-server one. It implies
the existence of two types of components:
· Server. Usually large, this component is designed to provide a set of software services that are available to the remote parties. The services are described in a manner dependent on the particular communication technology, and may be more or less related (functionally) to each other. This type of component implies a significant amount of centralization in the system, as it is the single place that implements complex functionality.
· Client. This component is traditionally designed as lightweight, and its main purpose is to use the services provided by a server. By doing so, it employs a usually limited functionality that processes the data received from its counterpart, and in most cases it presents it to the user.
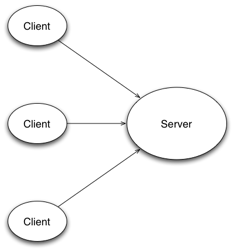
Figure 1 Clent-Server
In a client-server architecture, the usual deployment scenario implies a single server (or few ones) and a comparatively higher number of clients. The centralization specific to this architecture can create several problems at the runtime, such as the following:
· The communication to the single server can become too intense, especially when the number of clients is large. This may cause high traffic to the server’s network node, which in turn may create service availability problems.
· The server may act as a bottleneck in the system that limits the system’s performance and usability. Depending on the server’s efficiency in providing the services, and on the computational power provided by the hardware and software environment it relies on, this may become a significant problem, especially when the system must be scaled up to serve large numbers of clients
· The limited number of servers (usually only one) may present problems for the system availability. As the entire application functionality depends on the functioning of the server, a software or hardware issue that stops it from working effectively renders the entire application inoperable.
· The maintenance of a centralized server can be difficult, especially when it provides many, loosely-related functionalities. Servers can become too big and too complex, and the restructuring or reengineering needs that may arise at a point in the system’s lifetime can imply significant engineering problems.
Modern distributed application developments tend to overcome these problems by adopting other architectures, by distributing the services to several independent servers, or by designing the servers to be easily scaled or split into several entities if necessary.
2.2 Peer-to-Peer
In this architecture, the components of the distributed system have equally important roles. Each component (a peer) can provide services for others to use, and, at the same time can use the services provided by the others. In a way, a peer acts successively as server and client, according to the system needs at a stage or the other in its functioning.
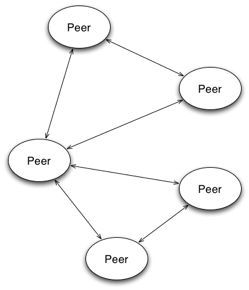
Figure 2 Peer to Peer
The fundamental trait of this architecture is that the components are balanced, and there usually is no centralized point in the system. This effectively counteracts the disadvantages of the server-client architecture, by providing a way of designing highly scalable and flexible distributed software applications. However, the architecture has an important problem, and it is related to its very basic principle of balancing the components. The fact that there is no central point, may create difficulties in the process of the component discovery at the runtime.
That is, the system must implement strategies that make the already running components
of the application reachable by the newer ones. This is done by including the component deployment information in each node of the application, or – more frequently – by using a server-based functionality to register and locate the running components. The latter method affects in a degree the balanced nature of the system, but as it is involved only on a single, very specific point in the component’s lifetime, it is usually accepted as a minor compromise.
2.3 Three-Tier
This architecture describes the application as consisting of three logically distinct sets of functionalities. Each tier consists of system entities with a very specific role, and the architecture is an extension of the server-client architecture, as the dependencies between the tiers are unidirectional. That is, the third tier acts as server for the second one, while the second provides services to the entities in the first tier.
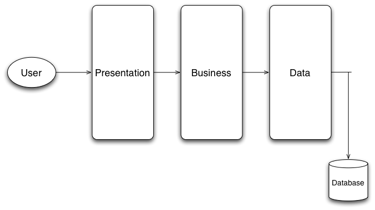
Figure 3 Three Tier
The architecture defines three tiers. In the software-specific context, they can also be referred as functionally-distinct software layers:
1. Presentation. The entities in this layer are responsible for the functionality that interacts with the user. They are lightweight software components that present data to the user (via an interface) and allow the user control and data validation.
2. Logic or Business. This layer is responsible for the implementation of the main functionality of the application, such as the algorithms that process data, and provide the features requested by the user.
3. Data. The entities in this layer are responsible for managing the persistent data objects manipulated by the business layer. It usually implies a database that stores the information, and consists of the software entities that model the stored data (as object-oriented data abstractions, for instance).
2.4 Multiple Tiers
This is an extension of the three-tier architecture, and refers to the case where several layers are involved in providing the software functionality, as more that three logical functionalities are considered necessary for the design. The most frequent implementation is when the user services are provided by more than one application. For example, this is the case when a web application forwards the user requests to a three-tiered enterprise application, specialized to provide the requested feature.
2.5 Other architectures
The design of distributed software applications is not limited to the above types of architectures. The designers may use a combination of the ”mainstream” approaches, and can also consider the specific issues required by the system’s functionality. For example, if a system must consist of several equally important peers, at a point in its functioning, there may occur the need of electing a component as temporary leader. For this purpose, the requirements of the chosen leader election algorithm have to be taken into consideration, and the components can be – for instance – designed as connected in a synchronous ring, to fulfill the respective algorithm’s constraints [Lyn97].
Moreover, components can be connected to each other in more complex ways, such as trees or even generalized graphs of inter-communicating entities that act as clients and servers to each other at the same time.
3 Communication Technologies
In order to communicate remotely, distributed applications depend on specialized infrastructures that provide the lower-level functionality of sending or receiving data over the network, in a synchronous or asynchronous manner, depending to the system requirements.
The infrastructures distributed software systems use for communicating are
important in that they directly influence the way the distributed architecture is implemented.
Some technologies imply a specific architecture, while others allow several or even unlimited architectural choices. More importantly, the communication technology usually imposes a set of specific constrains on the development of the application, that are frequently in the form of specific constructs in the applications source code. This makes the technology-related information highly relevant in an analysis, for detecting the distribution-related concerns within a software system.
We describe briefly the most frequently used communication technologies, and their main characteristics.
3.1 Protocol stacks
The protocol stacks [Tan02] describe facilities included in the modern operating systems that provide support for network communication to the application level. The design of a protocol stack is dependent on a chosen reference model that represents the software architecture of the parts of the operating system providing the network services. A stack describes several layers of abstraction, each introducing protocols that deal with a particular problem related to the data transmission and reception. The most frequent case of such a design is the ubiquitous TCP/IP stack, present in virtually all current operating systems capable of providing network connectivity.
The TCP/IP stack is based on a respective TCP/IP layered model.
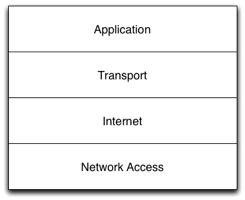
Figure 4 The TCP/IP Protocol Stack
It consists on four layers, with the following roles:
· The Network Access Layer deals with all the details concerning the transmission of the data provided by the superior layer, its encoding and the transmission of datagrams to a remote host.
· The Internet Layer represents the network as a set of interconnected subnetworks, and deals with the routing of data from a host to another. This layer defines the IP address that identifies the network interfaces and is used when routing the information.
· The Transport Layer defines protocols that deal with the higher-level concerns in transmitting data, such as maintaining the communication channels, error control, fragmentation and sequence of data arrival. There are two specific protocols at this layer, one being connection-oriented (TCP), and one connectionless (UDP).
· The Application Layer describes protocols used by the applications, such as FTP (File Transfer Protocol), HTTP (Hypertext Transfer Protocol), SMTP (Simple Mail Transfer Protocol), and so on.
The TCP/IP stack is accessible from the application through primitives specific to the operating system and to the programming language. Such a primitive is the one known as the socket, with is widely used implementation as a BSD Socket. In UNIX, sockets are implemented (from the application’s perspective) as descriptors that can be created and used by the programs. The language-specific libraries provide specific functions that create and manipulate these primitives, which in turn call the correspondent operating system services.
3.2 Remote procedures or methods
This technology places itself at a higher level of abstraction than the direct usage of sockets. The purpose is to provide the programmers with communication-related services that are used in programs in the a natural way, specific to the programming language.
The chosen strategy is to allow the program to call procedures remotely, that is procedures that reside on a program running at a different location. The most representative case is the Remote Procedure Calls technology [Ste99] specific to the UNIX [SR05, Rob05, Cos01] environments. Similar mechanisms are employed by more complex middleware systems, such as CORBA [Pop98, Gra06].
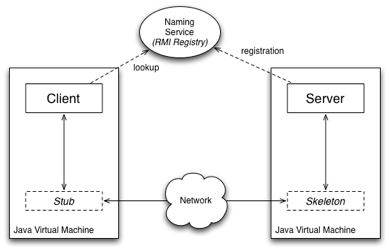
Figure 5 Remote Method Invocation
In the object-oriented context, this technology translates in invoking methods
of objects instantiated at a remote location. One of the most representatives technologies
is the Remote Method Invocation (RMI), specific to the Java environment [RR02, Gra06, CVM03]. In RMI (see Figure), an application that wants to communicate via the network must follow a set of specific requirements related to the implementation:
· The methods that need to be made available remotely must be gathered in special Java interfaces called remote interfaces. Each remote interface must extend the java.rmi.Remote interface provided by the standard Java packages, as a marker for the methods’ network-aware functionality.
· The actual implementations of the methods are done in server classes that implement the remote interfaces, either directly, or via a hierarchy of interface extensions. The server classes must either inherit a RMI-specific provided class (called UnicastRemoteObject), or explicitly call a static method in that class that exports its functionality to the network.
· The client classes use the server functionality by referring the remote interfaces.
They do not have direct dependencies with the server classes; instead, the Java virtual machine-specific implementation will hide the actual communication and provide the clients with remote references to the servers. In the earlier versions of Java, this implied the automatic generation of a set of infrastructure classes called stubs, and skeletons which represented the actual channels of communication between the parties.
· The server classes can register themselves to a naming service, so that they are discoverable by the clients. Both actions imply specific calls of RMIprovided methods.
3.3 Messaging systems
Services for communicating via the network can be also provided by systems that may be implemented as applications on their own. An example of such applications are the message-oriented service providers, which are complex systems dealing with the creation, manipulation, and persistence of application-defined messages. Applications can connect to the messaging systems and use them as intermediaries that send or receive messages; components of the application can send a message, and other components may receive them, all details of the actual sending or receiving being dealt with by the infrastructure.
An example of messaging infrastructure is Java Message Service (JMS [MHC00]. As it is, JMS is not an actual system, but a specification of messaging systems that vendors may implement in order to provide standardized message-oriented communication in the Java environment. A JMS application consists of the following system actors:
· Clients, that are the entities that create, receive and send messages;
· Messages, used in communication, with a content defined by the application;
· JMS Provider, the actual implementation of the messaging system.
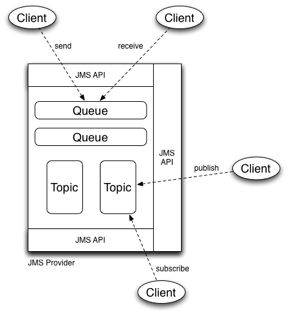
Figure 6 Java Message Service
The JMS messaging infrastructure must provide the following set of communicationrelated
primitives, that can be used by the applications depending on the type of messaging they need:
· A Connection Factory, which is used to create the connection between the client application and the messaging system
· A set of JMS Destinations, representing the resources the clients access, and that deal with the message manipulation. JMS defines two types of destinations, as support for the two major paradigms in message-oriented systems:
· Point-to-Point, represented with message queues available for the clients to enter or extract messages;
· Publish-Subscribe, represented by the so-called Topic destinations, that can be used by clients for publishing messages or subscribing to various message types.
3.4 Application Servers
A different class of technologies is represented by the Application Servers. An application
server is a software environment that manages the application by providing it with a set of specific, high-level services. The application is deployed inside the application server, and is heavily dependent on it. The entire development of the application must follow strict rules in both its design and implementation, and the deployment-specific configurations.
A very popular platform that employs an application server is Java2 Enterprise Edition (J2EE), with its Enterprise Java Beans technology [BMH06]. The applications that use this environment must be built using the three-tier architecture, and the technology provides means for creating the different types of entities, and services for distribution, persistence or transactions. EJB defines the following types of application entities, called enterprise beans:
· Entity beans, placed at the data layer, representing the entities that model in an object-oriented approach the data stored in a database;
· Session beans, places at the business layer, implement the logic functionality in the system. They can be of two types:
· Stateful, that are able to maintain their internal state between the client calls,
· Stateless, that do not maintain the state and are consequently lightweight in comparison with their counterparts;
· Message-driven beans, specialized entities able to subscribe and react to messages in a JMS environment, so that asynchronous application behavior can be implemented.
The clients at the presentation layer are normal Java applications (classes) that connect using specific techniques to the enterprise beans.
4. Component Deployment
One of the important aspects that must be taken into consideration when
designing or analyzing a distributed software system is the information that
specifies the way the different components of the system are dispersed over the
network. The deployment information is sometimes vital to understand the core
characteristics of the system, as it is directly related with its distributed
architecture.
The deployment information is specified in various ways, and it is highly dependent on the
communication technology the system relies on. The information can specify one or more of the following attributes of the distributed application:
· The network-specific address of each system component. This is a specification that shows which parts of the system (modules, packages, sets of classes) are deployed on which hardware nodes in the network.
· The relation between the component deployed in a node and the other local entities that may be related to the system, such as libraries, databases, application containers and so on.
· The dependencies between a component and its other remote counterparts that belong to the distributed application. Sometimes, configuration information specifies which are the addresses of the remote parties, or which are the component’s “neighbors” (nodes to communicate with) in the particular distributed architecture of the application.
Bibliography
[BMH06] Bill Burke and Richard Monson-Haefel. Enterprise JavaBeans 3.0
(5th Edition). O’Reilly Media, Inc., 2006.
[Cos01] Dan Cosma. UNIX - Aplicat¸ii. Editura de Vest, Timisoara, Romania,
, ISBN 973-36-0338-4, 2001.
[CVM03] Dan Cosma, Stejarel Veres, and Adrian Petru Mierlutiu. Aplicat¸ii
software distribuite. Editura de Vest, Timisoara, Romania, ISBN
973-36-0377-5, 2003.
[Gra06] Jan Graba. An Introduction to Network Programming with Java.
Springer-Verlag New York, Inc., 2006.
[Lyn97] Nancy A. Lynch. Distributed Algorithms. Morgan Kaufmann, San
Francisco, CA, USA, 1997.
[MH00] Richard Monson-Haefel. Enterprise JavaBeans. O’Reilly & Associates,
Inc., 2nd edition, 2000.
[MH99] Richard Monson-Haefel. Enterprise JavaBeans. O’Reilly, 1999.
[MHC00] Richard Monson-Haefel and David Chappell. Java Message Service.
O’Reilly & Associates, Inc., Sebastopol, CA, USA, 2000.
[Pop98] Alan LaMont Pope. The CORBA reference guide: understanding
the Common Object Request Broker Architecture. Addison-Wesley
Longman Publishing Co., Inc., Boston, MA, USA, 1998.
[Rob05] Arnold Robbins. Unix in a Nutshell, Fourth Edition. O’Reilly Media,
Inc., 2005.
[RR02] David Reilly and Michael Reilly. Java: Network Programming and
Distributed Computing. Addison Wesley, 2002.
[Sie96] Jon Siegel. CORBA Fundamentals and Programming. John Wiley
and Sons, 1996.
[SR05] Richard W. Stevens and Stephen A. Rago. Advanced Programming
in the UNIX(R) Environment (2nd Edition). Addison-Wesley Professional,
2005.
[Ste99] W. Richard Stevens. UNIX network programming, volume 2 (2nd
ed.): interprocess communications. Prentice Hall PTR, Upper Saddle
River, NJ, USA, 1999.
[Tan02] Andrew Tanenbaum. Computer Networks. Prentice Hall Professional
Technical Reference, 2002.
[TS01] Andrew S. Tanenbaum and Maarten Van Steen. Distributed Systems:
Principles and Paradigms. Prentice Hall, 2001.
[Wu99] Jie Wu. Distributed Systems Design. CRC Press LLC, 1999.