This project is based on the concept of B-trees discussed in Lecture on Various Trees
![]() This project is optional.
Submitting a complete and good project
in time brings two award points !
This project is optional.
Submitting a complete and good project
in time brings two award points !
The project is individual and personal work. Plagiarism from any source is considered a serious offence. If a project presented by a student is detected as not being the result of his own work, this will lead to failing to pass the ADA exam: projects are optional, you do not have to do them - but if you do, then submit only your own work!
The project has a hard deadline - saturday, 01.04.2023. You must submit your projects using the corresponding assignments on the Virtual Campus. A submission must contain the source code and a readme file explaining your work.
Students will also do a public presentation of their projects in class.
If you have questions related to this project, pleas address them by VirtualCampus messages or by email to ioana.sora@cs.upt.ro
The figure below presents a small example of a datafile with an index. The datafile in this example contains 9 records having the record size 20 bytes (1 byte the key and 19 bytes the value).
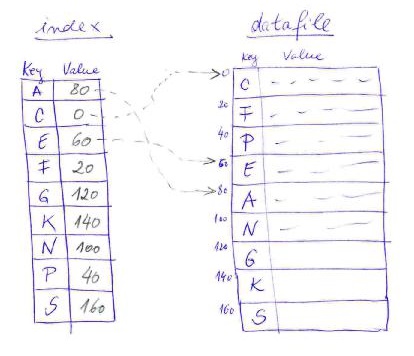
An index can be stored in-memory or on-disk (as a persistent index). If the datafile contains a huge number of records, the size of the index results also very big and may not fit into the available physical memory, requiring the use of persistent index on disk.
The index file must be implemented by using persistent B trees or B+ trees.
The principles of B trees have been briefly presesnted in the lecture in week 4.
The detailed description of operations on B trees can be found in [CLRS] - chapter 18.
A B tree that acts as an index for a datafile will contain key-value pairs. The B-tree keys are equal with the keys of the datafile records, while the B-tree-values are equal with the offset in the datafile where the record starts.
A B tree node contains n key-value pairs and n+1 links to child nodes. The number of children may vary between t and 2*t, where t is a constant chosen as the minimum degree of the tree.
If the B tree is persistent, it will be stored as a file on disk, in the following way: The file contains a number of fixed-size records, where every record corresponds to a B-tree node and contains: the counter of actual children n, and space for an array of (2*t-1) key-value pairs and 2*t children links. A child link is stored as the offset, within the same file, of the record corresponding to the child node. The file has a header, which contains information such as the offset of the root node, and maybe additional information such as the number of levels, or configuration information such as t=the degree of the B tree and the size of a key.
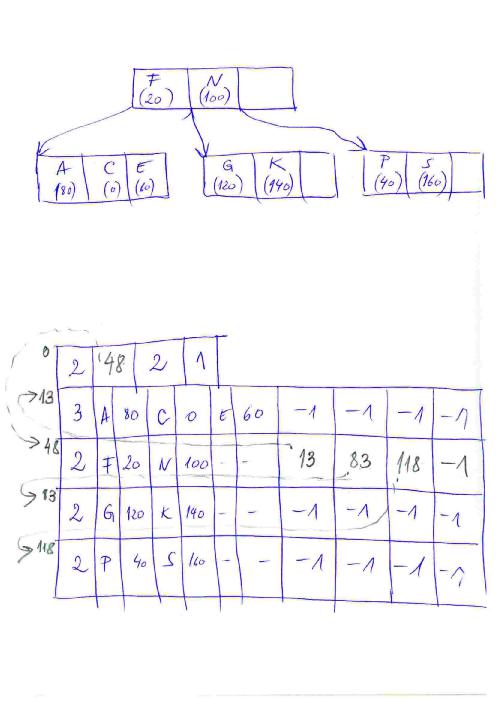
The picture below presents the example of a small B-tree containing key-value pairs. The degree of this tree is t=2, thus every node has a number of elements (key-value) between 1-3 and between 2 and 4 children. The tree is stored in a file, having a header and after this 4 fixed-size data records corresponding to the 4 tree nodes. In the small example depicted in this picture, the offsets in files have been considered integer values on 4 bytes; Attention for the real, "big" situations: 4 bytes are not enough to represent offsets that can appear in very big files !
You can read about the usage of B trees in real databases and filesystems in wikipedia link.
A version of B trees are the B+ trees. The difference is that in a B+ tree, values are stored only in leaves while intermediate nodes contain only copies of keys to guide the search. In addition, leaf nodes may include a link to the next leaf node to speed sequential acces.